R 语言入门
本文简介了一些 R 语言的基础知识,希望读者能够理解并能利用 R 语言进行数据统计分析与绘图的方法。R is a free software environment for statistical computing and graphics.
R 是一款集数据分析与绘图功能于一体的编程语言环境(A Programming Environment for Data Analysis and Graphics),生物信息的数据统计或绘图任务一般都可使用 R 完成。R 官网为:https://www.r-project.org/。
R 是优秀的统计工具,同时它也是一种开放的编程语言,语法简单易学,非常灵活,可编制自己的函数扩展现有的功能。R 属于 GNU 系统的一个自由、免费、源代码开放的软件,最初由新西兰奥克兰大学的 Ross Ihaka 和 Robert Gentleman 开发(两人名字都以 R 开头,因此称为 R),现在由“R 核心团队(the R Core Team)”负责开发。R 是现今最受欢迎的数据分析和可视化平台之一,可在多种平台下运行,包括 Windows、macOS 和 Linux 系统等。 做生物信息分析是避免不了使用 R 语言的,特别是 R 的 bioconductor 社区,在基因组学,尤其在单细胞测序数据分析上,已经是独步江湖了。
现在很多学术期刊都对分析软件有版权要求,而免费的分析工具可以使你在这方面不会有什么担心。另一方面,如果学术界出现一种新的数据分析方法,那么要过很长一段时间才会出现在商业软件中。但开源软件的好处就在于,很快就会有人将这种方法编写成扩展包,或者你自己就可以做这件工作。
安装与运行
最新的 R 软件可以从 CRAN(Comprehensive R Archive Network)网站下载,网址为:http://cran.r-project.org。鼠标单击“Download R for Windows”链接,下载适用 Windows 系统的版本,并选择下载基础(base)安装软件包。CRAN 有许多镜像站点,打开 CRAN 网页,点击左边的 Mirrors 链接,可以选择一个下载速度比较快的中国(China)镜像站点,如中国科技大学的镜像(https://mirrors.ustc.edu.cn/CRAN/)。下载后安装程序后,鼠标双击该文件按提示默认安装即可。
对于 Ubuntu 系统,只要运行命令:
apt-get install r-base在Mac OS X系统安装R语言更为简单,进入R语言官网,单击“Download R for (Mac) OS X”,下载pkg格式文件并安装即可。程序安装成功后,可以在Applications文件夹下找到并运行R。
运行
安装后可以在桌面或开始菜单找到“R”图标来运行。若你使用的是 64 位 Windows 系统,R 在默认安装条件下,会生成两个 R 图标,一个为 32 位软件(如 R i386 3.5.1),另一个为 64 位软件(如 R x64 3.5.1),数字为 R 的版本号。一般运行 R x64 3.5.1 即可。
 图 1 R 运行界面
图 1 R 运行界面
如图 1 所示,打开 R 后,就会显示控制台窗口(R Console),在其命令提示符 (>)后可以输入命令或表达式(expressions),回车后就输出命令运行结果:
> 2*3
[1] 6
因此,R 可以当计算器用,这里结果前的[1]表示 6 是结果里的第一个元素(此例仅有一个,结果可以有多个元素)。
> R.Version() #查看R版本
此命令将给出你系统所安装的 R 版本等信息。在 R 的命令行中#后面的内容是不执行的,注释符#代表后面是命令的注释。注意:R 是一种大小写敏感(case sensitive)的语言,输入命令要区分大小写!
如要退出 R,可使用命令:
> q() #或quit()
退出 R 前会询问是否保存当前的工作空间(workspace),工作空间含有当前会话(session)定义的所有变量。不保存工作空间,则这些变量的数据就会丢失。如果保存工作区,下次运行 R 时只要在文件菜单选“加载工作空间”就可以导入此会话的所有命令与变量。
运行脚本
在命令提示符(>)后,每次只能输入并执行一条命令。R 也可以一次性执行写在脚本文件中的一组命令。编写 R 脚本的方法如下:
- 鼠标点击 R 窗口的文件菜单,选择”新建程序脚本“,就可打开 R 编辑器,
- 在其中可输入多行命令,
- 再用 R 窗口的”执行代码“按钮(工具栏第三个图标)可运行全部代码,或先用鼠标选择部分代码,再执行此部分代码。
[!TIP] R 编辑器内可用快捷链"Ctrl+R"逐行运行当前光标所在行的代码, "Ctrl+Enter"运行全部代码。
查看帮助
R 要查看函数的说明,可以通过 help()或它的快捷方式(?)来查看:
> help("log10")
>?"log10"
如果你不知道什么函数名,但知道函数的一些相关内容,可以通过 help.search()它的快捷方式(??)查找帮助。如你要找一个函数来算一些数值的标准差,可以查找在描述中包含"deviation"的函数:
> help.search("deviation")
> ??"deviation"
R 作为一个开源软件有强大的社区支持,可容易获得社区帮助,国外活跃的社区有 GitHub 和 Stack Overflow 等,国内的 R 语言社区有统计之都(COS)及其旗下的 COS 论坛。
变量
变量是程序存储数据的基础,能够存储任何数据。变量可以看成内存空间(地址)的别名,变量的值代表其对应内存空间中存储的值。R变量名称是由字母、数字以及点(.)或下划线(_)组成。R 创建的所有变量(标量、矢量、矩阵等)都是对象(objects)。变量的名字称为符号,变量的取值是对象。通过变量赋值就可以使用变量名来读取变量值。R 语言可用箭头(<-)或等号(=)来给变量赋值,一般建议用箭头符号(<-)。
> x <- 2*3 #数值
> y = "AUGGUGCC" #字符串,注意为英文双引号!
如果只输入变量名,那么就会显示这个 R 对象的内容:
> x
[1] 6
也可以使用 print()函数显示变量内容:
> print(x)
[1] 6
注意 R 语言是一种区分大小写的解释型语言,R 语言的变量名要区分大小写!
R 语言中的所有事物都是对象(bojects),如向量、列表、函数和环境等。R 语言的所有代码都是基于对象的操作,而变量则是调用对象的重要手段。 可以用 ls()函数将当前运行环境中的对象都列出来:
> ls()
[1] "x" "y"
函数 rm()用来删除对象,如果要删除所有对象,可以使用:
> rm(list=ls())
R对象可以用它们的名称和内容来表示,也可以通过对象的数据类型即属性来表示。为了理解这些属性的用处,以一个在{1,2,3}中取值的变量为例:这个变量可以是一个整数变量(如巢中蛋的个数),或者是一个分类变量的编码(如某些甲壳类动物的三种性别:雄,雌和雌雄同体)。显然,对这个变量的统计分析在以上两例中是不相同的,对象R的属性在R中提供着所需要的信息。一般来说,对于作用于一个对象的函数,其表现取决于对象的属性。所有对象都有两个内在属性:类型与长度。类型是对象元素的基本种类,共有四种:数值型、字符型、复数型和逻辑型(FALSE/TRUE)。虽然也存在其他类型,但是并不能用来表示数据,如函数或表达式。长度是对象中元素的数目。对象的类型和长度可以分别通过函数model和length得到。
>x <- 1
>mode(x)
[1]"numeric"
>length(x)
[1]1
对于一个向量,用它的类型或长度足够描述数据,而对于其他对象则另需要一些额外信息,这些信息由外在的属性给出。如表示对象维数的是dim,一个2行2列矩阵的dim是[2,2],而其长度是4.
基本数据类型
R 中的所有变量都有一个类(class),表明此变量属于什么类型。R有6种基础数据类型:
- 逻辑型 (logical):TRUE,FALSE
- 数值型 (numeric):实数或小数,如1.22
- 整型 (integer):整数,如12
- 字符型 (character):文本数据,如"good","爸爸"
- 原型 (raw):字节数据,用于存储二进制数据,如48 65 6c 6c 6f
- 复数型 (complex):包含实部和虚部的数值,如4i+1 最常用的是前四种,例如,大部分的数字是 numberic 类型,逻辑值是 logical 类型。
R 对象还可按内部存储类型(type)分为向量(vector),因子(factor),矩阵(matrix),数组(array),数据框(data frame),表格(table)和列表(list)。 其实,因为 R 没有标量类型(scalar type),所以严格地说,数字向量应该是 numeric 类,逻辑向量是 logical 类。在 R 中“最小的”数据类型是向量。 R 对象的内部存储类型(type)、对象的模式(mode)等分类,可使用 class()函数、typeof()和 mode()函数查询对象的属性。这些大多是 R 语言历史遗留问题,实际中你只需要使用对象的类。
> x = pi*10^2 #pi是圆周率
> class (x) #x的class
[1] "numeric"
> typeof (x) #x的type
[1] "double"
在 R 语言中,还有 5 种经常使用的特殊值:NULL、NA、NAN、Inf。
- NULL 表示变量为空;
- NAN(Not a number)表示相应的计算是没有数学意义或不能正常执行的;
- NA(not available)表示缺失值;
- Inf 和-Inf 表示正无穷与负无穷。 可以通过 is.null(), is.na(), is.nan(), is.infinite()函数来判断一个对象是否为相应的特殊值。 R使用特殊的常量值NA来表示数据集中缺失的值。你可以将NA值赋给任何其他类型的R数据元素。数据出现缺失值可能是数据未收集、未知或不相关,需要与空值或零值区分开来。如果我们还不知道商店出售的商品价格,则价格是缺失的,这绝对不是零,否则是免费赠送商品。
数据类型定义了R存储变量中包含的信息和可能值的范围。R中常见的数据类型有:
- 数值型数据类型存储十进制数,而整数数据类型存储整数。如果创建一个包含数字但没有指定数据类型的变量,默认情况下,R会将其存储为数值型。然而,R通常可以根据需要在数值和整数数据类型之间自动转换。数值类型为double,它是双精度浮点数的缩写,数值与双精度是可以互换的。
- 字符型数据类型用于存储最多65535个字符的文本字符串。
- 逻辑型数据类型是一个简单的二元变量,只有两个可能值:真或假。例如,在一个关于学生的数据集中有一个变量Married,对于已婚学生设置为真,对于未婚学生设置为假。
- 因子类型用于存储分类值。一个因子的每一个可能值都称为一个水平。例如,可以使用一个因子来存储个人的性别,男/女就是一个水平。有序因子是因子数据类型的特例,其中级别的顺序是十分重要的。例如,如果我们有一个包含低、中、高风险评级的因子,则顺序很重要(低<中<高),有顺因子保留了这一意义。
R有一组is函数,用于测试对象是否属于特定的数据类型,如果是则返回真,如果不是则返回假。
- is.logical()
- is.numeric()
- is.integer()
- is.character()
- is.factor()
这里注意整数型与数据值的区别,默认数字为数值型,如果我们想显式地创建一个整数,需要给数字添加L后缀。
> y <- 1
> is.numeric(y)
[1] TRUE
> is.integer(y)
[1] FALSE
> yint <- 1L
> is.integer(yint)
[1] TRUE
R提供一组as函数,用于将数据从一种类型转换成另一种类型。这些函数接受对象或向量作为参数,并试图将其从现在数据类型转换为函数名称的数据类型。但是,这种转转换并不总是可能的。如可将一个数值1.5转换为字符串"1.5",但没有任何合理的方法将字符串"apple"转换为整数型。
> as.character(1.5)
[1] "1.5"
> as.integer("1.5")
[1] 1
> as.integer("apple")
[1] NA
Warning message:
NAs introduced by coercion
> as.logical(1)
[1] TRUE
> as.logical(0)
[1] FALSE
基本运算符
运算符是连接变量的桥梁,使变量与变量之间能够执行特定的操作而产生新的数据,这就是计算机的基本工作--计算。
- 数学运算符:运算后给出数值结果,如+,-,,/,^, %%, %/%, %%
- 比较运算符:运算后给出判别结果(TRUE, FALSE),如>, <, <=, >=, ==, !=
- 逻辑运算符:与(&, &&)、或(|, ||)、非(!)。其中&可对向量进行循环比较,而&&与||只比较向量的第一个元素。
- 其它还有赋值运算符(<-或=)、取值及条件运算符([]或.)等。
> 5 < 6
[1] TRUE
数据结构
基本数据类型是编程语言中最简单、最基本的数据单元。它定义了数据的种类和特性。而数据结构是一种将多个值组织在一起的方式,以便更有效地处理和操作这些值。
R 语言中有多种复杂数据结构,包括向量、矩阵、数据框(与数据集类似)以及列表(各种对象的集合)等。
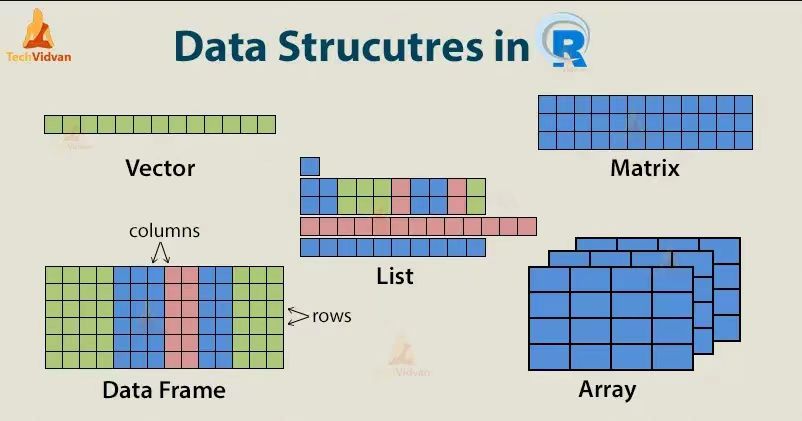
向量是一个变量;因子是一个分类变量;数组是一个k维的数据表;矩阵是数组的一个特例,其维数k=2。注意,数组或矩阵中所有元素都必须是同一种类型;数据框是由一个或几个向量或因子构成,它们必须等长,但可以是不同的数据类型。列表可以包含任何类型的对象,包括列表。时间序列数据包含一些额外的属性,如频率和时间。
向量(vector)
标量只能有一个元素,而向量可以有多个元素构成。但每个在向量中的元素的类型必须相同,如数值或字符。创建向量可以用函数 c(),即 combine/concatenate 函数,表示连接:
> myvector <- c(8, 6, 9, 10, 5)
> myvector
[1] 8 6 9 10 5
前面的[1]是向量 myvector 的第一个元素的 index。我们可以通过变量名加上中括号包括的索引值来读取变量的元素:
> myvector[4]
[1] 10
> myvector[2:4] #提取从位置2到4之间的元素
[1] 6 9 10
> myvector[myvector > 8] #提取向量中大于8的元素
[1] 9 10
> myvector[-4] #利用负号(-)删除特定位置的元素
[1] 8 6 9 5
当需要在向量中添加元素时,使用append()函数。
>newvec <- append(myvector, 22) #在最后面添加元素
>newvec<- append(myvector,11,after=0) #在最前面添加元素,after指定位置
>newvec
[1] 11 8 6 9 10 5
针对在一定范围内,有顺序的数据可以用冒号(:)生成:
> 1:6 #生成在1到6范围的整数
[1] 1 2 3 4 5 6
> x = sample(1:200000,10000) #从1,...,200000中随机不放回地抽取10000个值作为样本
> z = sample(x, 10, rep=TRUE) #从有放回地随机抽取10个值作为样本
> print(z)
[1] 150517 48627 141260 179097 159144 12734 179539 91287 197402 13812
> sample(1:100,20,prob=1:100) #从1:100中不等概率随机抽样, 各数目抽到的概率与1:100成比例
向量化计算是 R 语言特有的一种并行计算方式,即当你对一个向量进行操作时,程序会对向量中每个元素进行分别计算,计算结果以向量的形式返回。向量化计算基本可以取代循环计算,高效的完成计算任务。
> x=rep(1,10); y=1:3
> x*z #向量乘法(如果长度不同,R给出警告和结果)
[1] 1 2 3 1 2 3 1 2 3 1
Warning message:
In x * z : longer object length is not a multiple of shorter object length
- 与向量有关的函数 函数: min(x)最小值, max(x)最大值, which.min(x)显示最小值所在位置, which.max(x)显示最大值所在位置, sum(x)加, length(x)x 的长度,mean(x)均值, median(x)中值, var(x)方差, sd(x)标准差, sqrt(x)平方根, abs(x)取绝对值, unique(x)去冗余, intersect(x)取交集, union(x,y)取并集, setdiff(x,y)差集, setequal(x,y)判断两向量是否相同(对顺序无要求), identical(x,y)判断两向量是否相同(对顺序有要求)。
因子(Factor)
因子属于字符型向量的一种,因子可用来存储类别变量(categorical variables)和有序变量,如性别(男女)、成绩(高中低)等。这类变量不能用来计算而只能用来分类或计数。一个因子不仅包括类别变量本身,还包括变量不同的可能水平(即使它们在数据中不出现)。一般用 factor()函数创建一个因子,下面是一些例子:
> X <- c(2,3,5,1,2,3,4,1)
> Xfactor <- factor(X)
[1] 2 3 5 1 2 3 4 1
Levels: 1 2 3 4 5
> Y <- factor(1:3, levels=1:5)
> Y
[1] 1 2 3
Levels: 1 2 3 4 5
> Z <- c("A", "B", "C", "D","B","A")
> Zfactor <- factor(Z)
> Zfactor
[1] A B C D B A
Levels: A B C D
函数 levels()用来提取一个因子中可能的水平值:
> levels(Xfactor)
[1] "1" "2" "3" "4" "5"
函数 summary()给出一个因子中水平的频率表:
> summary(Zfactor)
A B C D
2 2 1 1
注意,数字形式的因子中的元素不能作为数值进行计算,但可以通过 as.numeric()函数转换成数字。
> Xvector <- as.numeric(Xfactor)
同理,as.vector()可以把因子转变成字符串向量:
> Zvector <- as.vector(Zfactor)
矩阵(matrix)
矩阵是由相同数据类型组成的二维数组。矩阵和数组可看成是带维数的向量,矩阵就是一个二维的数值数组,每个元素都具有相同的数据类型(数值型、字符型或逻辑型)。创建矩阵的一个方便的方法是使用 matrix()函数:
> X <- matrix(1:12, nrow=3, byrow=T)
[,1] [,2] [,3] [,4]
[1,] 1 2 3 4
[2,] 5 6 7 8
[3,] 9 10 11 12
注意矩阵默认是以按列形式填充,这里 byrow=T 将矩阵改成以按行形式填充。 对矩阵进行操作的常用函数有 rownames(), colnames(),转置函数 t()等。
> rownames(X)<-LETTERS[1:3] #LETTERS是包含大写字母A-Z的内置变量
> X
[,1] [,2] [,3] [,4]
A 1 2 3 4
B 5 6 7 8
C 9 10 11 12
> dim(X) #行列数目
[1] 3 4
> dim(X) <- c(4,3)
> X
[,1] [,2] [,3]
[1,] 1 6 11
[2,] 5 10 4
[3,] 9 3 8
[4,] 2 7 12
> t(X) #注意转置函数t()是小写t,与大写T代表“TRUE"不同
A B C
[1,] 1 5 9
[2,] 2 6 10
[3,] 3 7 11
[4,] 4 8 12
> apply (x, 1, mean) #对行(第一维)求均值
> apply (x, 2, sum) #对列(第二维)求和
数据框(data frame)
数据框可以理解为“表格”,由一个或几个向量或因子构成。每个列都有唯一的列名,且必须是等长的,但可以是不同的数据类型。数据框也是二维数组(2D array),与矩阵不同的地方是数据框中的数据可以是各种类型同时存在,如数值、字符串或者因子等。数据框是生物医学研究中最常用的数据记录格式,数据框中每行代表一个观测研究对象,每列代表研究对象一个特性的实验结果(图 2)。
 图 2 数据框
图 2 数据框
可以用函数 data.frame()创建数据框:
> x <- data.frame(Name = c("tom", "Jimmy", "alice"), Age = c(18, 20, 41), Score = c(90, 30, 77))
> x
Name Age Scorep
1 tom 18 90
2 Jimmy 20 30
3 alice 41 77
[!TIP] data.frame()会自动把strings的数据转换成factors,若不想转换,则额外设定参数“stringsAsFactors=FALSE”。
还可以使用函数 rbind()按行组合成数据框,或 cbind()按列组合成数据框。
可以使用内置命令 str()(structure 的简写)来查看数据框的基本结构属性:
> str(x)
'data.frame': 3 obs. of 3 variables:
$ Name : Factor w/ 3 levels "alice","Jimmy",..: 3 2 1
$ Age : num 18 20 41
$ Score: num 90 30 77
> names(x) #查看数据的变量名字
下面介绍数据框中数据的提取方法:
> x[2,] #提取某一行
Name Age Score
2 Jimmy 20 30
> x$Name #常用数据框的列名提取某一列,或用x[,1]
[1] tom Jimmy alice
Levels: alice Jimmy tom
> x[x$Name == "alice",]$Age #或x[3,2],提取某个点的数据
[1] 41
> x[1:2,1:3] #提取前两行,前三列
> head(x) #头几行数据,与x[1:10,]相同
列表(list)
列表可用来存储多种不同类型的数据,包含向量、矩阵、数据框,甚至另一个列表。与数据框不同的是,数据框一般具有相同的长度,而列表并无此特殊规定,所以数据框可以看成是长度相同的列表。 可以用函数 list()创建列表:
> mylist <- list(name="Fred", wife="Mary", myvector)
> mylist
$name
[1] "Fred"
$wife
[1] "Mary"
[[3]]
[1] 8 6 9 10 5
列表中的元素 are numbered,可以用索引值来取得,与 vector 不同,是列表名加上两个括号来包括的索引值来读取:
> mylist[[2]]
[1] "Mary"
> mylist[[3]]
[1] 8 6 9 10 5
列表中的元素 are named,列表元素可以通过列表名加上“$",再加上元素名来读取:
> mylist$wife
[1] "Mary"
可以 atrributes()函数来查找元素名:
> attributes(mylist)
$names
[1] "name" "wife" ""
可以看到列表 mylist 有两个元素有名称,"name" 与"wife"。 使用 unlist()函数可将列表转换成向量,方便我们进行算术运算。
表格(table)
另一个可能遇到的 R 对象是 table 变量。如我们有一个小孩名字的矢量 mynames,用 table()函数就可以得到一个 table 变量,包括每个名字及其对应的孩子数:
> mynames <- c("Mary", "John", "Ann", "Sinead", "Joe", "Mary", "Jim", "John", "Simon")
>mytable <- table(mynames)
> mytable
mynames
Ann Jim Joe John Mary Simon Sinead
1 1 1 2 2 1 1
与列表一样,可以通过双中括号来得到 table 变量中的元素:
> mytable[[4]]
[1] 2
> mytable[["John"]]
[1] 2
R 语言编程
流程控制
到现在,我们主要用到了 R 语言对简单表达式赋值的语法。默认情况下代码是按从上到下的顺序执行的,但是 R 作为一门编程语言也允许有条件执行和循环重复执行代码。流程控制语句可以选择相应分支运行代码,或循环重复执行一段代码。
- (a) 条件执行(conditional statements)
if (条件) 表达式
if (条件) 表达式 1 else 表达式 2
比如下面的代码,判断 p 值是否显著(小于 0.05):
p <- 0.1
if(p <= 0.05){
print("p <= 0.05!")
}else{
print("p > 0.05!")
}
表达式内的多条语句要用一对花括号括起来,以开括号({)开始,并以闭括号(})结束。
- (b)循环结构(loop structure)
for(变量 in 向量) 表达式
while(条件) 表达式
注意: while 语句只要条件是真就会执行表达式。这个判断在循环的最开始,所以表达式可能从来不被执行。
v <- LETTERS[1:5]
for (i in v){
if(i == 'D'){
next
#break
}
print(i)
}
# next:跳过循环的当次迭代,不终止循环,开始循环的下次迭代。
[1] "A"
[1] "B"
[1] "C"
[1] "E"
# break:当循环中遇到break语句时,循环立即终止。
[1] "A"
[1] "B"
[1] "C"
函数
函数(function)是编写可复用代码的基础结构。每个函数是组织好的,用来实现单一或相关功能的代码段。函数运行形式为函数名后面紧跟括号()[函数名()],并将需要的参数放入括号中。一般 R 语言的函数都需要参数,即传给函数的变量,来进行一些操作,如 log10()需要一个数值,计算基于 10 的 log 值:
> log10(100)
2
R 语言的函数又分为高级函数与低级函数,高级函数内部嵌套了复杂的低级函数,如 plot()是高级绘图函数,有大量的参数可选,函数本身会根据参数的数据类型,经过程序内部的函数判别之后,绘制相关类型的图形。
使用 R 内置函数可执行基本的统计任务。当你经常需要对一些数值做同样的运算,而 R 没有内置的函数可用,可以自己编写一个函数。 R 语言的自定义函数形式为: function (对象, 选项=) 例如下面自编的函数可以计算输入数值的平方加 20:
> rfunc <- function(x) { return(20 + (x*x)); }
这个函数先计算 x 的平方,然后加上 20。return()返回计算得到的值。这个函数就可以被重复使用:
> rfunc(10)
[1] 120
> rfunc(25)
[1] 645
注意,函数中如有几个表达式一定要用花括号包括在一起。当没有用 return()函数,R 函数默认返回最后一行表达式结果。
rcal<-function(x,y)
{
z <- x^2 + y^2;
result<-sqrt(z);
result;
}
> rcal(3,4) #调用函数
[1] 5
当你写了许多函数可以打包成一个程序包(package)供别人使用。R 程序包是多个 R 函数、数据、帮助文件、预编译代码以一种定义完善的格式组成的集合。Windows 下的 R 程序包是已经编译好的 zip 包。
常用函数
R 有许多内置函数,如 mean(), length(), print(), plot()等。下面介绍一些常用的函数,关于函数更详细的说明,请查看 R 的帮助文档。
数值处理
- seq()函数生成一组有规律的数值
> seq(2, length=4, 5)
[1] 2 3 4 5
> seq(0, 10, by = 2) #从0到10,每次增加2
[1] 0 2 4 6 8 10
> seq(-5, 5, length.out=100) #在区间[-5,5]生成100个数
- rep()函数生成一组有重复的数据
> rep(1:3, each=2, time=3)
[1] 1 1 2 2 3 3 1 1 2 2 3 3 1 1 2 2 3 3
- runif()函数生成均匀分布的随机数,如 runif(10, min=0, max=3)
> x <- runif(10, 0, 3) #生成10个在0到3之间的随机数
> x
[1] 0.66087875 2.42687999 2.14814697 0.12664629 0.09590261 0.02613993
[7] 1.10544266 1.26475600 1.67144153 2.83656489
- rnorm()函数生成正态分布的随机数。
> rnorm(10, mean=2, sd=3) #生成10个平均值为2,方差为3的正态分布的随机数
[1] 1.061149769 0.524625250 4.549493933 7.403447844 5.364699910
[6] 4.939417826 -0.003161921 1.808738263 3.938803880 2.667750108
- round()函数针对数值进行四舍五入的处理,设置参数为保留小数点后的位数。
> round(x, 1)
[1] 0.1 0.6 2.5 2.4 1.5 2.8 1.8 0.5 1.0 1.2
- length()函数给出向量里元素的长度(个数)
> length(x)
[1] 10
- summary()函数对数据进行简要 summary 统计。
> summary(x)
Min. 1st Qu. Median Mean 3rd Qu. Max.
0.1296 0.6784 1.3907 1.4411 2.2368 2.8303
字符处理
- paste()是针对字符向量的连接编辑函数,默认在连接的字符串之间加上一个空格。如果不需要空格,则可以使用 paste0()函数。
> Y <- paste(LETTERS[1:5], 1:5, sep="-")
> Y
[1] "A-1" "B-2" "C-3" "D-4" "E-5"
- strsplit()是用于拆分字符串的函数
> strsplit(Y[1], "-")
[[1]]
[1] "A" "1"
- substr()函数是用于提取字符串的一部分内容
> substr("abcdef", 2,4)
[1] "bcd"
数据读取
在进行数据文件读取前,需要指定工作路径,可用 getwd()与 setwd()函数来显示或设置工作路径:
> getwd() # Get Working Directory
> setwd("c://bigbook//20R") #Set Working Directory
# 注意Windows路径用两条斜线, 路径要用反斜杠"/"或者双斜杠"\\"。
> dir() #显示目录下的内容
工作路径也可以通过 R 菜单(文件/改变工作目录)手工进行选择目录(图 3):

图 3 改变目录
根据不同数据文件类型,可以选择不同的 R 函数来读取数据,下面介绍两种常用的文件(txt 与 csv) 读取方法:
- 文本数据可使用 read.table()函数
> dat <- read.table("file1.txt", header=TRUE)
由于 read.table()默认以空格当间隔符,如果数据中存在缺失项,那么软件会错误地把前后两个或多个空格当成一个间隔符,造成导入数据出现错误。因此,在使用该函数的时候,特别要注意把缺失项使用"NA"来表示出来。 保存数据到文件可用 write.table()函数。
> write.table(data, file="filex.txt", sep="\t")
- CSV 格式文件可用 read.csv()函数
> dat <- read.csv("file1.csv", header=TRUE)
CSV 文件为以逗号分隔的数据,这样不会出现因数据缺失而发生错行的情况,但要注意数据中的内容不能有逗号出现,特别当数据项中有描述性语句时需格外注意。 同样,保存数据到 CSV 文件可用 write.csv()函数:
> write.csv(data, file="filex.csv", sep="\t")
R语言绘图
R语言系统有非常强大的绘图函数,绘图函数的结果直接输出到一个“绘图设备”上。绘图设备是一个绘图窗口或是一个文件。绘图参数控制绘图选项,可使用缺省值,并可用函数par()修改。 R语言有两种绘图函数:高级绘图函数(high-level plotting functions),创建一个新的图形;低级绘图函数(low-level plotting functions),在现存的图形上添加元素。 R语言中最常用的绘图函数是plot(),它可以接受多个不同的对象作为参数绘制散点图。其它常用的绘图函数有 hist()直方图, barplot()条形图, pie()饼图,boxplot()箱线图等。 这里用 seq()生成 x 数据,runif()生成 y 数据,之后用默认参数运行 plot()作图:
x <- seq(1:10)
y <- round(runif(10, min=0, max=10), 1)
plot(x, y)
可以通过 plot()的参数修改,得到更佳的图片展示效果(图 4),
> plot(x,y,ylim=c(0,12), main="plot parameters", xlab="length", ylab="height", pch=19, cex=c(1:3))
 图 4 plot 结果
图 4 plot 结果
一般常用的参数如下:
(1)xlim, ylim 参数可以定义 X 轴与 Y 轴的刻度范围。
(2)main 参数给定图片的标题;xlab 与 ylab 用来定义 X 轴与 Y 轴的名称。
(3)pch 参数用于定义绘制点的样式,pch 用数字表示各种不同的图形标记,如数字 1 是空心圆(默认值),2 是正三角,3 是加号等。
(4)cex 参数定义图标的大小,默认值为 1,可用一个矢量如 c(1:3)设置相对于默认值的放大倍数。
(5)col 参数用于设定颜色,R 语言中预定了 657 种颜色,可以使用 color()查看。
(6)plot()函数还可以绘制出点的连线图,type 参数用于定义线条的类型,常用的类型有:"p"显示点,"l"显示线条, "b"显示点和线, "o"显示点在线上;lwd 参数设定线的宽度,lty 参数设定线条的性状。
> plot(x,y,ylim=c(0,12), main="plot parameters", xlab="length", ylab="height",pch=20, cex=1.5, type="b", lwd=2, lty=2)
另外,绘图参数与低级绘图函数可以进一步改善图形。如果需要绘制不止一个数据的曲线,可以使用低级绘图函数lines()来完成,可用points()函数增加点,用text()可以增加显示文本,用arrows()画出一个箭头,用rect()画出一个方框等(图 5)。
> z <- round(rnorm(10, sd=2, mean=4), 1)
> lines(x,z,pch=1, cex=1.5, type="l", lwd=2, lty=1, col="red")
> legend("topright",c("black", "red"), col=c("black","red"), lwd=2)
> text(2, 10, "This is text")
> rect(4,10,6,11, col="green")
> arrows(6,8,7,8)
 图 5 plot作图参数
图 5 plot作图参数
R作图结果默认都是输出到同一个图形设备(Graphic device),后一个绘制的图会覆盖前一个图。如果你想同时绘制多种类型的图表,可以使用 dev.new() 函数新建Device窗口,并在新窗口中绘制图表。 注意,鼠标选中某个Device窗口,并不能使当前窗口成为激活状态,需要使用dev.set()函数设置。不过,用鼠标选中某个 Device 窗口,可手动导出当前窗口的图表。可以使用 dev.list()函数查看当前 Device 窗口列表。
>dev.list()
>dev.set(2) #改变当前为设备窗口2
如果要在一个图形设备绘制多个图,可使用 par()设置默认的图形参数:
>par(mfrow=c(1,2)) #图形组合,一行两列图
 图 6 图形组合
图 6 图形组合
图片保存
- GUI 界面 完成绘制图形后,点击菜单文件(file)->另存为(save as),然后选择合适的文件格式。
- 命令行 如果想在命令行内把 R 作图直接保存为文件,如产生一个 TIFF 或 PDF 格式的图片,可以利用 tiff()或 pdf()打开这些文件类型的设备。执行绘图命令后,必须要用 dev.off()函数关掉当前活动的图形设备。否则,已绘制的图形将被后面的屏幕输出所覆盖。例如,下面命令将图片保存到工作目录的 PDF 文件:
> tiff(filename="test.tif", width=1000, height=1000)
> b <- c(1,3,2,6,4,7)
> plot(b)
> dev.off()
该代码将产生一个 tiff 图像,高和宽都是 1000 像素。在纸上,这通常比 10cm 宽一点。如果你发现图形中的文字已经变得很小,可以调整图的边距和文本大小。这些图形参数可以通过 par()函数来设置,例如可以用参数 mar 设置图形到边距的距离。 各种图形格式都有对应的命令,如 png(),jpeg(),tiff()等。对于 PDF 图形设备,宽度与高度不是用像素指定,而是以英寸为单位。原则上,你仍然可以使用像素,但别忘了要将像素除以分辨率,否则将得到一个巨大的文件。例如,要得到 300DPI 的分辨率的文件,可以将像素的数值除以 300:
> pdf(filename="test.pdf", width=1000/300, height=1000/300)
> pdf(filename="test.pdf", width=10, height=10)
- R (ggplots): data visualization
程序包(package)
R 程序包是多个 R 函数、数据、帮助文件、预编译代码以一种定义完善的格式组成的集合。R 语言具有丰富的程序包,提供了大量的数据分析方法与功能。但许多 R 包并没有集成在基础包中,如果要使用它们需要额外安装。R 语言综合档案库 CRAN(The Comprehensive R Archive Network)包含了大量开发者贡献的扩展包,截至 2020 年 5 月 30 日,总共有 15707 个包,涉及统计分析、数值计算、量化投资、金融分析、数据挖掘、机器学习、生物信息学、生物制药、数据可视化等各个领域。
安装 R 包
- 在 Windows 或 MacOS 中,你可以简单地使用 R 窗口的菜单(“程序包”)来安装 R 包。也可以使用以下命令来安装:
> install.packages("mypkg")
> install.packages("mypkg", dependencies=TRUE) #指定安装依赖包用命令
> install.packages("mypkg", repos='mirror.lzu.edu.cn/CRAN') #指定CRAN国内镜像
- 在 Linux 系统中,如果想让安装的 R 包让所有用户用,必须先以超级用户权限运行 R(如 sudo R),然后 R 包会安装到系统的库目录,不然只会安装到用户目录,而其他用户将无法读取。
- Windows 下的 R 程序包是已经编译好的 zip 包。可以下载 zip 包到本地,使用命令 install.packages("zip 包路径", repos=NULL)安装。
安装 Bioconductor 包
Bioconductor(www.bioconductor.org)是专门为生物信息开发的一系列R包的总集,可用于生物信息数据的处理、注释、分析与可视化等。每年都会更新两版本,2021年5月,最新的Bioconductor(Bioc3.13)已经包含2042个软件包,965个注释包,406个实验数据包及29个重要的分析流程。由于Bioconductor包更新频率较高,并需要与R语言版本严格兼容,Bioconductor包的下载与安装方法与一般R包略有不同。 Bioconductor 包的安装方法如下:
>source("https://bioconductor.org/biocLite.R") #https or http
>biocLite("yeastExpData")
[!TIP] bioconductor 默认的下载地址都在国外,所以下载速度十分慢。但可以用它在国内的镜像来下载相关包,提高下载速度。 可指定一个离你最近的国内镜像:
options(BioC_mirror="http://mirrors.ustc.edu.cn/bioc/") #中科大镜像
options(BioC_mirror="https://mirrors.tuna.tsinghua.edu.cn/bioconductor") #清华镜像
同样,可指定基础 R 包的国内源:
options("repos" = c(CRAN="https://mirrors.tuna.tsinghua.edu.cn/CRAN/"))
R 版本 3.6 以上版本推荐使用以下命令安装:
> if(!requireNamespace("BiocManager", quietly=TRUE)) install.packages("BiocManager")
> BiocManager::install("mypkg") #直接将需要安装的包名作为参数
R 包的使用
R 包的存储目录称为库(library)。在使用某个包前,需要使用 library()命令载入程序包到工作环境中以进行相关的运算:
>library("yeastExpData") #导入包
载入 R 程序包后,调用程序包内的函数,与 R 内置的函数调用方法一样。在一次会话中,包只需要云载入一次,每次重启 R 软件后都需要重新载入 R 包。
同样,如果不需要程序包可以用 detach()函数卸载程序包:
>detach("yeastExpData")
表 1 R 中常见的使用包的函数
| 函数名称 | 含义 |
|---|---|
| install.packages() | 下载并安装包 |
| update.packages() | 更新包 |
| remove.packages() | 卸载包 |
| liabrary() | 加载(导入)包 |
| .libPaths() | 显示库所在的目录 |
注:你可以通过 search()命令查看当前环境下导入的包情况。
使用 dplyr 包进行数据处理
近年来,数据处理工作越来越多使用 dplyr 包,在 R 中使用 dplyr 包使数据处理更高效,它的速度比 R 基础函数快,并允许将多个函数连接使用。按照前面描述的方法安装 dplyr 包,然后加载到 R 语言环境:
> library(dplyr)
下面使用 R 基础包中的鸢尾花数据集(iris)为例介绍它的使用方法。下面代码将生成一个按 Species 分组的包括 Sepal.Length 的均值的表格,均值保存在变量 average 中。
> summarize(group_by(iris, Species), average = mean(Sepal.Length))
# A tibble: 3 x 2
Species average
<fct> <dbl>
1 setosa 5.01
2 versicolor 5.94
3 virginica 6.59
dplyr 允许使用管道操作符%>%帮助阅读代码。通过管道操作符,可以将函数连接在一起,从而避免函数之间的嵌套使用。可以从要使用的数据框开始,将多个函数连接在一起,使得第一个函数的函数值或参数可以传递给下一个函数,以此类推。下面的代码将得到和前面同样的结果:
> iris %>% group_by(Species) %>% summarize(average = mean(Sepal.Length))
# A tibble: 3 x 2
Species average
<fct> <dbl>
1 setosa 5.01
2 versicolor 5.94
3 virginica 6.59
distinct()函数可以找出一个变量中的唯一值。count()函数自动对变量进行分类计数。filter()函数可以基于一个匹配条件选取特定的行。
> distinct(iris, Species) #查看变量Species中有哪些不同的值
Species
1 setosa
2 versicolor
3 virginica
> count(iris, Species) #计算每个Species的数量
Species n
1 setosa 50
2 versicolor 50
3 virginica 50
> filter(iris, Sepal.Width > 4.0) #选取Sepal.Width大于4.0的行
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.7 4.4 1.5 0.4 setosa
2 5.2 4.1 1.5 0.1 setosa
3 5.5 4.2 1.4 0.2 setosa
接下来看一下这个数据框。首先按照 Petal.Length 的值对行进行降序排列:
> df <- arrange(iris, desc(Petal.Length))
> head(df)
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 7.7 2.6 6.9 2.3 virginica
2 7.7 3.8 6.7 2.2 virginica
3 7.7 2.8 6.7 2.0 virginica
4 7.6 3.0 6.6 2.1 virginica
5 7.9 3.8 6.4 2.0 virginica
6 7.3 2.9 6.3 1.8 virginica
通过可 select()函数选出感兴趣的变量,创建两个数据框,一个由 Sepal 开头的列组成,另一个由 Petal 开头的列和 Species 列组成,也就是不以 Se 开头的列组成。在 select()函数中指定这些特定的列即可完成上述任务,也可以用 starts_with 语法:
> iris2 <- select(iris, starts_with("Se"))
> iris3 <- select(iris, -starts_with("Se"))
> theIris <- bind_cols(iris2, iris3) #按列合并两个数据框,相当于基础包中的cbind()函数
> head(theIris)
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5.0 3.6 1.4 0.2 setosa
6 5.4 3.9 1.7 0.4 setosa
可以看到合并后的 theIris 与 iris 完全一样。如果你想使用 rbind()函数那样按行连接数据,可以使用 bind_rows()函数。如果有行名称或其它关键字,还可以使用 left_join()和 inner_join()这样的函数来连接数据。 iris 数据集中一共有 150 个观测值,如果想知道 Sepal.Width 中有多少个唯一值,可以使用下面这个代码:
> summarize(iris, n_distinct(Sepal.Width)) #查看有多少个唯一值
n_distinct(Sepal.Width)
1 23
几乎所有大数据集中都存在重复测量值,使用 dplyr 删除重复数据也非常简单。假设想创建一个只由 Sepal.Width 中的唯一值组成的数据框,并在数据框中保留所有列,可以使用下面的代码:
> dedup <- iris %>% distinct(Sepal.Width, .keep_all = T)
> str(dedup)
'data.frame': 23 obs. of 5 variables:
$ Sepal.Length: num 5.1 4.9 4.7 4.6 5 5.4 4.6 4.4 5.4 5.8 ...
$ Sepal.Width : num 3.5 3 3.2 3.1 3.6 3.9 3.4 2.9 3.7 4 ...
$ Petal.Length: num 1.4 1.4 1.3 1.5 1.4 1.7 1.4 1.4 1.5 1.2 ...
$ Petal.Width : num 0.2 0.2 0.2 0.2 0.2 0.4 0.3 0.2 0.2 0.2 ...
$ Species : Factor w/ 3 levels "setosa","versicolor",..: 1 1 1 1 1 1 1 1 1 1 ...
注意,这里使用管道操作符连接 iris 数据集和 distinct()函数,并在 distinct()函数中设定.keep_all = T,使得所有列都包括在新的数据框中,否则新数据框中就只有 Sepal.Width 一列。
References
- Peter Dalgaard, Introductory Statistics with R (R 语言统计入门), 人民邮电出版社, 2014
- Toivo GM Rebecca J Lai, Kate Haining, Greta Todorova, and Wilhelmiina. Introduction to R. Available from: https://gabymahrholz.github.io/Intro_to_R/index.html
- Chang W. R Graphics Cookbook, 2nd edition. Available from: https://r-graphics.org
- The R Graph Gallery: https://www.r-graph-gallery.com/
- 李东风,R 语言教程: https://www.math.pku.edu.cn/teachers/lidf/docs/Rbook/html/_Rbook/index.html
- Giorgi FM, Ceraolo C, Mercatelli D. The R Language: An Engine for Bioinformatics and Data Science. Life. 2022; 12(5):648. https://doi.org/10.3390/life12050648
- Cookbook for R 中文版:https://www.bookstack.cn/read/Cookbook-for-R-Chinese/040fb5e44c703675.md